Heute geht es mal um ein sehr spezielles Problem mit einer Lösung auf die ich gestern durch Probieren gekommen bin und sehr erstaunt war, dass das so funktioniert und offenbar sogar so vorgesehen ist. Zunächst ein paar Worte zum ursprünglichen Problem.
Ich arbeite im Institut mit Matlab 6.1, zwar schon etwas in die Jahre gekommen aber brauchbar. Für die Auswertung meiner Messdaten habe ich ein GUI programmiert wo ich zwei verschiedene Sachen gleichzeitig in einem axes-Objekt darstellen will. Normalerweise kann man hier mit den Funktionen hold und plot arbeiten, aber mir war das zu unflexibel und ich habe daher gleich die LowLevel-Funktionen benutzt. Ich habe in dem GUI das gewünschte axes-Objekt. Direkt darunter in der Objekthierarchie kommen bereits die line-Objekte, die auch plot erzeugt. Von Hand kann man sich die mit dem Befehl line erzeugen, die landen dann in dem aktuellen axes-Objekt, das man zuvor mit axes(axeshandle) festlegen sollte. Bei der Erzeugung der line-Objekte speichere ich das line-Handle um später direkt wieder drauf zugreifen und beispielsweise die zugrundeliegenden Daten ändern zu können.
Soweit so gut, nun ist es so, dass ich nicht bestimmen kann, wann der Benutzer die eine Sache zum Plotten anklickt und wann die andere. Oben erscheint aber immer die zuletzt gewählte. Genauso verhält sich der Befehl plot. Was zuerst geplottet wird, landet hinten, die nachfolgenden Sachen darüber. Das ist bei vielen Darstellungen egal, bei einigen aber nicht.
Der Trick um die Darstellungsreihenfolge – oder englisch z-Order – zu ändern klingt ein wenig wie »von hinten durch die Brust ins Auge«, funktioniert aber wunderbar. Um zu verstehen, was dort gemacht werden muss, schaut man sich am besten nochmal die Objekthierarchie an. Ein axes-Objekt beherbergt beliebig viele line-Objekte. Die Handles dieser Objekte kann man sich ausgeben lassen:
linehandles = get(gca, 'Children')
Die einzelnen Elemente des Vektors linehandles haben genau die Reihenfolge der Anordnung in z-Richtung wobei das erste Element das zu oberst angezeigte ist. Es spricht nichts dagegen, die Elemente umzuordnen und dem axes-Objekt wieder zuzuweisen, z.B. in umgekehrter Reihenfolge:
set(gca, 'Children', flipud(get(gca, 'Children')))
Ich war einigermaßen überrascht, dass das tatsächlich so funktioniert, da ich in der ausführlichen Matlab-Hilfe nie darüber gestolpert bin. Dass das wirklich so vorgesehen ist, sagt einem Matlab selbst, wenn man versucht der Eigenschaft Children etwas anderes als ein umgeordnetes selbst zuzuweisen:
??? Error using ==> set Children may only be set to a permutation of itself.
Damit das ganze noch ein wenig anschaulicher wird, habe ich noch ein kleines Skript geschrieben, dass die Sache nochmal illustriert:
% test data
a = rand(5,1)
b = rand(5,1)
c = rand(5,1)
% line handles
hp = plot([a b c]) % hp in order we plotted
ha = get(gca, 'Children') % reverse order
% vectors of line handles equal?
all(hp==ha) % not equal
all(hp==flipud(ha)) % should be equal, see above
all(sort(hp)==sort(ha)) % also equal
% thick lines
set(ha, 'LineWidth', 10)
title('original order')
legend('a','b','c') % order as in plot call
print(gcf, '-dpng', 'z-order-original.png')
% color of the most front line, should be c
get(ha(1), 'Color') % should be red aka [1 0 0]
% now flip lines, put c in the back
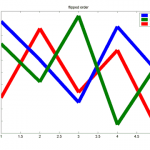
set(gca, 'Children', [ha(2) ha(3) ha(1)])
title('flipped order')
print(gcf, '-dpng', 'z-order-flipped.png')
% color of the most front line, should be b
ha = get(gca, 'Children')
get(ha(1), 'Color') % should be green aka [0 0.5 0]
Schaut man sich hier die erzeugten PNG-Bilder an, erkennt man, dass die Linie für die Datenreihe c zunächst ganz vorn und dann ganz hinten dargestellt wird:
-
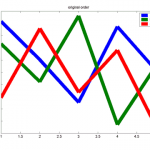
- drei zufällige Signale in normaler Reihenfolge